학습 플랫폼 이용자 구독 갱신 예측 해커톤 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
데이터 가설 설정
구독 유형과 구독 유지 여부
구독유형은 Basic과 Premium으로 구분되어있다.
- Basic이 Premium보다 가격이 저렴하기 때문에 유지율이 높을것 같다.
- Premium이 선호하는 난이도가 Basic보다 높을것이다.
- 완료한 총 코스 수가 많을 수록 커뮤니티 참여도도 높고 구독 유지를 할 것이다.
데이터 살펴보기
- user_id: 사용자의 고유 식별자
- subscription_duration: 사용자가 서비스에 가입한 기간 (월)
- recent_login_time: 사용자가 마지막으로 로그인한 시간 (일)
- average_login_time: 사용자의 일반적인 로그인 시간
- average_time_per_learning_session: 각 학습 세션에 소요된 평균 시간 (분)
- monthly_active_learning_days: 월간 활동적인 학습 일수
- total_completed_courses: 완료한 총 코스 수
- recent_learning_achievement: 최근 학습 성취도
- abandoned_learning_sessions: 중단된 학습 세션 수
- community_engagement_level: 커뮤니티 참여도
- preferred_difficulty_level: 선호하는 난이도
- subscription_type: 구독 유형
- customer_inquiry_history: 고객 문의 이력
- payment_pattern
- 사용자의 지난 3개월 간의 결제 패턴을 10진수로 표현한 값.
- - 7: 3개월 모두 결제함
- - 6: 첫 2개월은 결제했으나 마지막 달에는 결제하지 않음
- - 5: 첫 달과 마지막 달에 결제함
- - 4: 첫 달에만 결제함
- - 3: 마지막 2개월에 결제함
- - 2: 가운데 달에만 결제함
- - 1: 마지막 달에만 결제함
- - 0: 3개월 동안 결제하지 않음
- target: 사용자가 다음 달에도 구독을 계속할지 (1) 또는 취소할지 (0)를 나타냄
데이터 EDA

- 균등한 분포를 보이는 변수도 있고, 정규분포를 보이는 변수도 있고, 한 쪽으로 치우친 변수도 있다.Basic이 Premium보다 많다. Premium 구독자가 구독을 계속할 전망이다.
- Basic이 Premium보다 많다. Premium 구독자가 구독을 계속할 수 있다. →(첫 번째 가설 검증)
- 낮은 난이도를 더 선호한다.
- Payment Pattern은 특이한 분포가 없다.
- 상관관계 히트맵만으로는 변수끼리 유의미한 상관관계를 볼 수없다.
- 다만, community_engagement_level 과 total_completed_courses 비교적 상관관계가 제일 높다.
→(세 번째 가설검증)
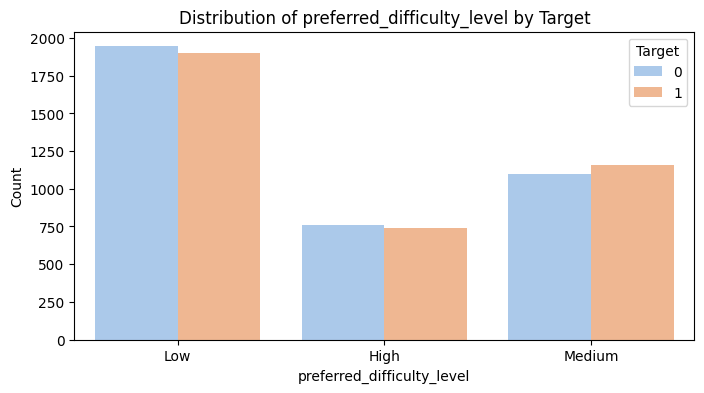
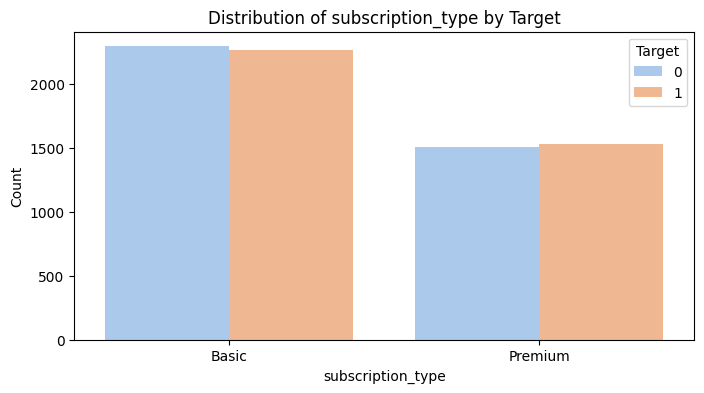
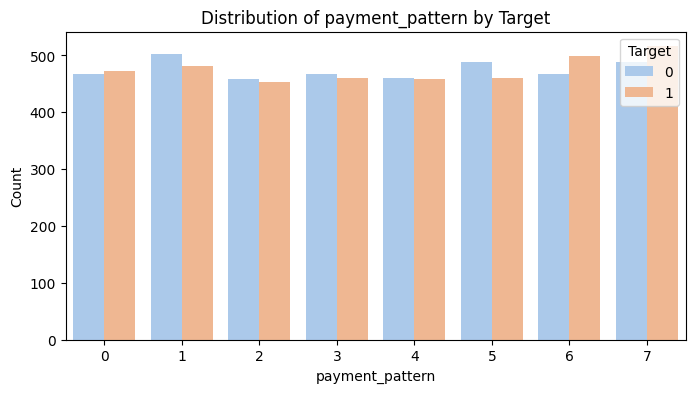
- 범주형 변수들 사이 역시 유의미한 분포 차이를 관찰하기 어렵다.
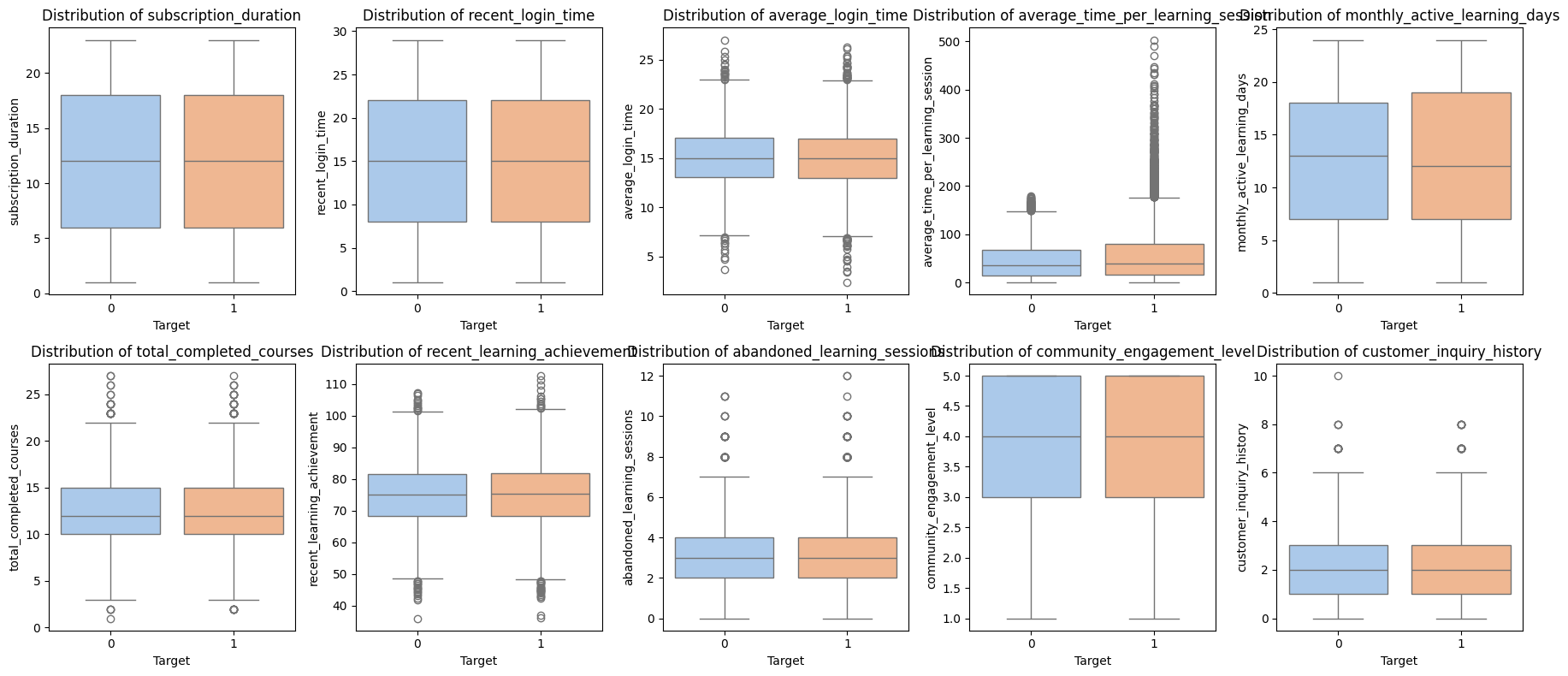
- 전체적으로 비슷해보이지만, average_time_per_learning_session(각 학습 세션에 소요된 평균시간(분))에서 target 1인 경우에 이상치가 많다.
범주형 변수들과 종속변수 간 관계는 독립으로 나왔다. 그 외 수치형 변수들 중에서는 '학습 세션에 할애하는 평균 시간'이 가장 크다.
카이제곱 검정: 범주형 변수 간 독립성 검증
1. 구독 유형과 구독 유지 여부는 독립이다.
- 귀무가설은 구독 유형과 구독 유지 여부는 관계가 없다.
- 대립가설은 '관계가 있다.'
- 통계량과 p-value를 확인해보자
- p-value 값이 0.05이하일 경우 귀무가설 기각: 두 변수 간 연관성이 있다.
1. 카이제곱 통계량: 0.9651279538193285
2. p-value: 0.32589826627361207
3. df: 1
구독 유형과 구독 유지 여부의 p-value는 0.3으로 유의수준 0.05보다 크므로 귀무가설을 채택한다. 즉, 구독 유형과 구독 유지 여부는 관계가 없다.
2. 선호하는 난이도와 구독 유지 여부는 독립이다.→(두 번째 가설 검증)
- 귀무가설은 선호하는 난이도와 구독 유지 여부는 관계가 없다.
- 대립가설은 '관계가 있다'
- 통계량과 p-value를 확인해보자
- p-value값이 0.05 이하일 경우 귀무가설기각: 두 변수 간 연관성이 있다.
1. 카이제곱 통계량: 4.95445899120559
2. p-value: 0.08397555825766137
3. df: 2p-value 값이 0.08로 유의수준 0.05보다 크므로 귀무가설을 채택한다. 즉, 선호하는 난이도와 구독 유지 여부는 관계가 없다.
3. 결제패턴과 구독 유지 여부는 독립이다.
- 귀무가설은 결제패턴과 구독 유지 여부는 관계가 없다.
- 대립가설은 '관계가 있다'
- 통계량과 p-value를 확인해보자
- p-value값이 0.05 이하일 경우 귀무가설기각: 두 변수 간 연관성이 있다.
1. 카이제곱 통계량: 3.3264772685914292
2. p-value: 0.8532485616136666
3. df: 7p-value 값이 0.85로 유의수준 0.05보다 크므로 귀무가설을 채택한다. 즉, 결제패턴과 구독 유지 여부는 관계가 없다.
로지스틱 회귀분석: 종속변수(구독 유지 여부)의 이진분류
로지스틱 회귀 분석을 통해 각 변수들의 변수 중요도를 살펴 보고자 한다.
1. 데이터 불러오기
(10000, 14)
2. 범주형 변수 더미화 하기 & 변수 선택
3. 학습/평가 세트 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 0)4. 정규화 하기
from sklearn,preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)5. 모델 생성/평가
- 모델의 정확도는 62% 테스트 데이터 셋을 통했을 때는 60%
model.score(x_train, y_train)0.622625model.score(x_test, y_test)0.6095
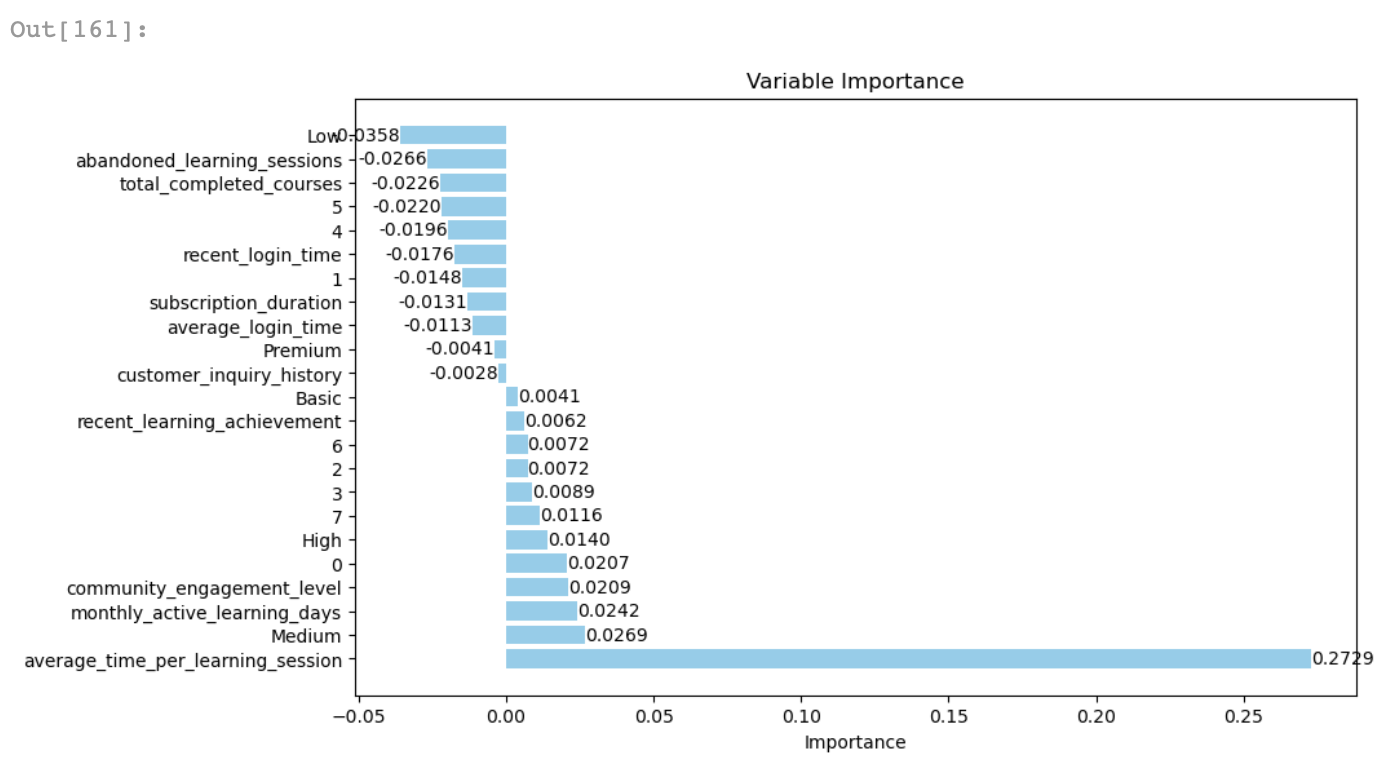
- 학습세션에 소요한 평균 시간이 구독 유지 여부에 가장 큰 영향을 미친다고 볼 수 있다
[코드 공유] GitHub
GitHub - jiyezzang/DA_3: 학습 플랫폼 이용자 구독 갱신 예측 해커톤
학습 플랫폼 이용자 구독 갱신 예측 해커톤. Contribute to jiyezzang/DA_3 development by creating an account on GitHub.
github.com
'데이터 분석 프로젝트' 카테고리의 다른 글
| [Kaggle/MYSQL]식품 배송 데이터분석 2️⃣Instacart Market Basket Analysis (0) | 2024.01.27 |
|---|---|
| [Kaggle/MySQL] 식품 배송 데이터분석1️⃣ Instacart Market Basket Analysis (0) | 2024.01.16 |
| [MySQL] VSCode와 MySQL 연결하면서 생긴 문제들☹︎(feat.sqlite3) (0) | 2023.11.28 |
| 데이터 분석 프로젝트 : 해외방송시장조사(주 이용 OTT 서비스) (1) | 2023.11.28 |
| [책]데이터 분석 프로젝트 시작 : 데이터 문해력 (1) | 2023.11.15 |